This entry is part of the “Deployment Quest” series.
In the previous article, we discussed a very simple monolithic deployment. One server with all of the relevant services necessary to make our application work. We discussed details such as drive layout, package installation, and some basic security controls.
In this article, we’ll expand that design a bit by deploying individual services and explain, along the way, why we do this. This won’t solve the single point of failure issues that we discussed previously, but these changes will move us further down the path of a reliable and resilient deployment.
Let’s do a quick recap first. Our single server deployment includes a simple website application and a database. We can break this up into two, possibly three distinct applications to be deployed. The database is straightforward. Then we have the website itself which we can break into a proxy server for security and the primary web server where the application will exist.
Why a proxy server, you may ask. Well, our ultimate goals are security, reliability, and resiliency. Adding an additional service may sound counter-intuitive, but with a proxy server in front of everything we gain some additional security as well as a means to load balance when we eventually scale out the application for resiliency and reliability purposes.
The security comes by adding an additional layer between the client and the protected data. If the proxy server is compromised, the attacker still has to move through additional layers to get to the data. Additionally, proxy servers rarely contain any sensitive data on them. ie, there are no usernames or passwords located on the proxy server.
In addition to breaking this deployment into three services, we also want to isolate those services into purpose-built networks. The proxy server should live in what is commonly called a DMZ network, we can place the web server in a network designated for web servers, and the database goes into a database network.
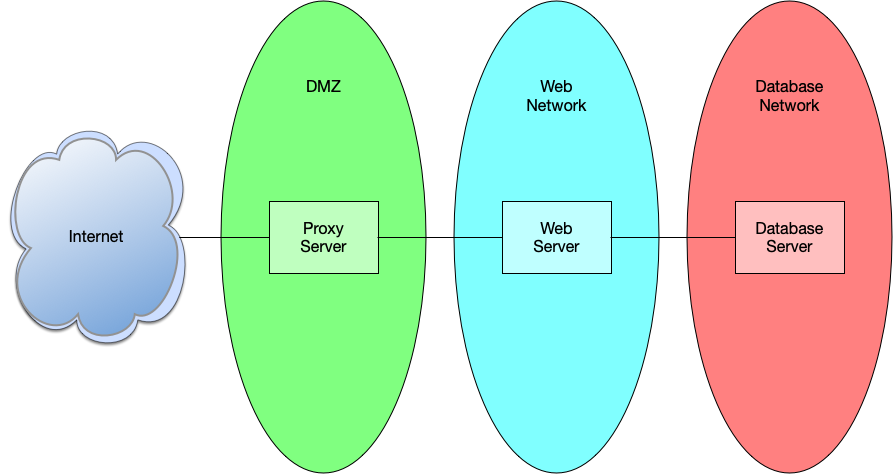
Keeping these services separate allows you to add additional layers of protection such as firewall rules that limit access to each asset. For instance, the proxy server typically needs ports 80 and 443 open to allow http and https traffic. The web server requires whatever port the web application is running on to be open, and the database server only needs the database port open. Additionally, you can limit the source of the traffic as well. Proxy servers are typically open to the world, but the web server only needs to be open to the proxy server, and the database server only needs to be open to the web server.
With this new deployment strategy, we’ve increased the number of servers and added the need for a lot of new configuration which increases complexity a bit. However, this provides us with a number of benefits. For starters, we have more control over the security of each system, allowing us to reduce the attack surface of each individual server. We’ve also added the ability to place firewalls in between each server, limiting the traffic to specific ports and, in certain instances, from specific hosts.
Separating the services to their own servers also has the potential of allowing for horizontal scaling. For instance, you can run multiple proxy and web servers, allowing additional resiliency in case of the failure of one or more servers. Scaling the proxy servers requires some additional network wizardry or the presence of a load balancing device of some sort, but the capability is there. We’ll discuss horizontal scaling in a future post.
The downside of a deployment like this is the complexity and the additional overhead required. Instead of a single server to maintain, you now have three. You’ve also added firewalls to the mix which also need maintenance. There’s also additional latency added due to the network overhead of communication between the servers. This can be reduced through a number of techniques such as caching, but is generally not an issue for typical web applications.
The example we’ve used, thus far, is quite simplistic and this is not necessarily a good strategy for a small web application deployment, but provides an easy to understand example as we expand our deployment options. In future posts we’ll look at horizontal scaling, load balancing, and we’ll start digging into new technologies such as containerization.