This entry is part of the “Deployment Quest” series.

SPOFs, or a Single Points of Failure, are the points in a system that can cause a complete failure of the overall system. These can be both technological and operational in nature. Creating a truly resilient system means identifying and mitigating as many of these as you can. Truly resilient systems minimize SPOFs and put mechanisms in place to handle any SPOFs that can’t be immediately dealt with and minimize the consequences of any given failure.
Single Point of Failure
A single point of failure is a part of a system that, if it fails, will stop the entire system from working. SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
Wikipedia
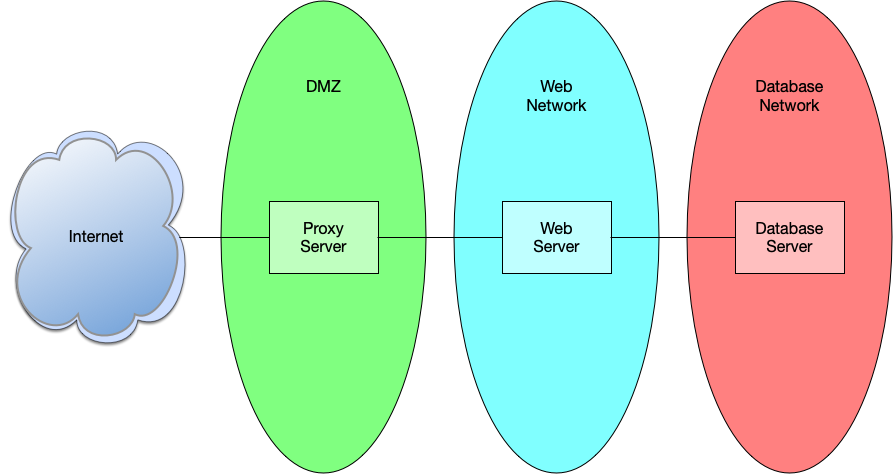
If we look back at the first post in this series, there are a multitude of SPOFs that need to be handled. Our first deployment is a single server with a single network feed. The following is a list of immediate SPOFs that need to be dealt with:
- Single network connection
- Single network interface
- Single server
- Single database
- Monolithic application
- Single hard drive
- Single power supply
All of these SPOFs are technological in nature. We didn’t explore the operational workflows around this deployment, so identifying non-technological is beyond this particular exercise.
In the second post, we discussed mitigation of some of these SPOFs. Primarily, we distributed services to multiple servers, mitigating the single server as a SPOF. However, the failure of any single service results in the failure of the whole.
Mitigating SPOFs comes down to identifying where you depend on a single resource and developing a strategy to mitigate it. In our previous example, we identified the server as a SPOF and mitigated it by using multiple servers. However, since we’re still dealing with single instances of dependent services, mitigating this SPOF doesn’t help us much.
If we duplicated each service and placed each on its own server, we’re in a much better situation. Failure of any single server, while potentially degrading overall service, will not result in the complete failure of the system. So, we need to identify SPOFs while keeping in mind any dependencies between components.
Now that we’ve deployed multiple copies of each service, what other SPOFs still exist? Each server only has a single power supply, there’s only one network interface on each server, and the overall system only has a single network feed. So we can continue mitigating SPOFs by duplicating each component. For instance, we can add multiple network interfaces to each server, deploy additional network connections, and ensure there are multiple power supplies in each server.
There is a point of diminishing returns, however. Given unlimited time and resources, every SPOF can be eliminated, but is that realistic? In a real world scenario, there are often constraints that cannot be easily overcome. For instance, it may not be possible to deploy multiple network connections in a given location. However, it may be possible to distribute services across multiple locations, thereby eliminating multiple SPOFs in one fell swoop.
By deploying to two or more locations, you potentially eliminate multiple SPOFs. Each location will have a network connection, separate power, and separate facilities. Mitigating each of these SPOFs increases the resiliency of the overall system.
In other situations, there may be financial constraints. Deploying to multiple locations may be cost prohibitive, so mitigations need to come in different forms. Adding additional network interfaces and connections help mitigate network failures. Multiple power supplies mitigate hardware failures. And deploying UPS power or, if possible, separate power sources, mitigates power problems.
Each deployment has its own challenges for resiliency and engineers need to work to identify and mitigate each one.