Ok, I’ve done it. I’ve installed the ActivityPub plugin and put this blog on the Fediverse. Why? Well, it’s new, it’s interesting, and I really want to see the Fediverse grow.
What is the Fediverse, you ask? Well, in a nutshell, it’s a network comprised of various types of social networks that use a common protocol to talk between them. That protocol is ActivityPub.
There are tons of different types of social networks you can use. Mastodon is the primary one folks know about. Mastodon is a social network similar to Twitter, Bluesky, etc. But there are others.
PeerTube is a Youtube style network for hosting videos.
PixelFed is an image sharing network. Think Imgur or Instagram.
Lemmy is a conversation platform similar to Reddit.
And there are a TON more! Each of these is an app you can run on your own, thus owning your own content and making whatever choices you want with respect to the content. And if you’re not interested in running your own instance, there are plenty of instances out there that you can join.
Right now I’m just experimenting to see how this works with a blog on the Fediverse, but I’m hoping it works out and I can get back to blogging on a regular basis.
“The advantage of a bad memory is that one enjoys several times the same good things for the first time.”
Friedrich Nietzsche
This post first appeared on Redhat’s Enable Sysadmin community. You can find the post here.
Memory is a funny construct. What we remember is often not what happened, or even the order it happened in. One of the earliest memories I have about technology was a trip my father and I took. We drove to Manhattan, on a mission to buy a Christmas gift for my mother. This crazy new device, The Itty Bitty Book Light, had come out recently and, being an avid reader, my mother had to have one.
We drove to Manhattan, on a mission to buy a Christmas gift for my mother. This crazy new device, The Itty Bitty Book Light, had come out recently and, being an avid reader, my mother had to have one.
After navigating the streets of Manhattan and finding a parking spot, we walked down the block to what turned out to be a large bookstore. You’ve seen bookstores like this on TV and in the movies. It looks small from the outside, but once you walk in, the store is endless. Walls of books, sliding ladders, tables with books piled high. It was pretty incredible, especially for someone like me who loves reading.
But in this particular store, there was something curious going on. One of the tables was surrounded by adults, awed and whispering between one another. Unsure of what was going on, we approached. After pushing through the crowd, what I saw drew me in immediately. On the table, surrounded by books, was a small grey box, the Apple Macintosh. It was on, but no one dared approach it. No one, that is, except me. I was drawn like a magnet, immediately grokking that the small puck like device moved the pointer on the screen. Adults gasped and murmured, but I ignored them all and delved into the unknown. The year was, I believe, 1984.
Somewhere around the same time, though likely a couple years before, my father brought home a TI-99/4A computer. From what I remember, the TI had just been released, so this has to be somewhere around 1982. This machine served as the catalyst for my love of computer technology and was one of the first machines I ever cut code on.
My father tells a story about when I first started programming. He had been working on an inventory database, written from scratch, that he built for his job. I would spend hours looking over his shoulder, absorbing everything I saw. One time, he finished coding, saved the code, and started typing the command to run his code (“RUN”). Accordingly to him, I stopped him with a comment that his code was going to fail. Ignoring me as I was only 5 or 6 at the time (according to his recollection), he ran the code and, as predicted, it failed. He looked at me with awe and I merely looked back and replied “GOSUB but no RETURN”.
At this point I was off and running. Over the years I got my hands on a few other systems including the Timex Sinclair, Commodore 64 and 128, TRS-80, IBM PS/2, and finally, my very own custom built PC from Gateway 2000. Since them I’ve built hundreds of machines and spend most of my time on laptops now.
The Commodore 64 helped introduce me to the online world of Bulletin Board Systems. I spent many hours, much to the chagrin of my father and the phone bill, calling into various BBS systems in many different states. Initially I was just there to play the various door games that were available, but eventually discovered the troves of software available to download. Trading software become a big draw until I eventually stumbled upon the Usenet groups that some boards had available. I spent a lot of time reading, replying, and even ended up in more than one flame war.
My first introduction to Unix based operating systems was in college when I encountered an IBM AIX mainframe as well as a VAX. I also had access to a shell account at the local telephone company turned internet service provider. The ISP I was using helpfully sent out an email to all subscribers about the S.A.T.A.N. toolkit and how accounts found with the software in their home directories would be immediately banned. Being curious, I immediately responded looking for more information. And while my account was never banned, I did learn a lot.
At the same time, my father and I started our own BBS which grew into a local Internet Service Provider offering dial-up services. That company still exists today, though the dial-up service died off several years ago. This introduced me to networks and all the engineering that comes along with it.
From here my journey takes a bit of a turn. Since I was a kid, I’ve wanted to build video games. I’ve read a lot of books on the subject, talked to various developers (including my idol, John Carmack) and written a lot of code. I actually wrote a pacman clone, of sorts, on the Commodore 64 when I was younger. But, alas, I think I was born on the wrong coast. All of the game companies, at the time, were located on the west coast and I couldn’t find a way to get there. So, I redirected my efforts a bit and focused on the technology I could get my hands on.
Running a BBS, and later an ISP, was a great introduction into the world of networking. After working a few standard school-age jobs (fast food, restaurants, etc), I finally found a job doing tech support for an ISP. I paid attention, asked questions, and learned everything I could. I took initiative where I could, even writing a cli-based ticketing system with an mSQL database backing it.
This initiative paid of as I was moved later to the NOC and finally to Network Engineering. I lead the way, learning everything I could about ATM and helping to design and build the standard ATM-based node design used by the company for over a decade. I took over development of the in-house monitoring system, eventually rewriting it in KSH and, later, Perl. I also had a hand in development of a more modern ticketing system written in Perl that is still in use today.
I spent 20+ years as a network engineer, taking time along the way to ensure that we had Linux systems available for the various scripting and monitoring needed to ensure the network performed as it should. I’ve spent many hours writing code in shell, expect, perl, and other languages to automate updates and monitoring. Eventually, I found myself looking for a new role and a host of skills ranging from network and systems administration to coding and security.
About this time, DevOps was quickly becoming the next new thing. Initially I rejected the idea, solely responding to the “Development” and “Operations” tags that make up the name. Over time, however, I came to realize that DevOps is yet another fancy name for what I’ve been doing for decades, albeit with a few twists here and there. And so, I took a role as a DevOps Engineer.
DevOps is a fun discipline, mixing in technologies from across the spectrum in an effort to automate away everything you can. Let the machine do the work for you and spent your time on more interesting projects like building more automation. And with the advent of containers and orchestration, there’s more to do than ever.
These days I find myself leading a team of DevOps engineers, both guiding the path we take as we implement new technology and automate existing processes. I also spend a lot of time learning about new technologies both on my own and for my day job. My trajectory seems to be changing slightly as I head towards the world of the SRE. Sort of like DevOps, but a bit heavier on the development side of things.
Life throws curves and sometimes you’re not able to move in the direction you want. But if you keep at it, there’s something out there for everyone. I still love learning and playing with technology. And who knows, maybe I’ll end up writing games at some point. There’s plenty of time for another new hobby.
This post first appeared on Redhat’s Enable Sysadmin community. You can find the post here.
I’ve spent a career building networks and servers, deploying, troubleshooting, and caring for applications. When there’s a network problem, be it outages or failed deployments, or you’re just plain curious about how things work, three simple tools come to mind: ping, traceroute, and netstat.
Ping
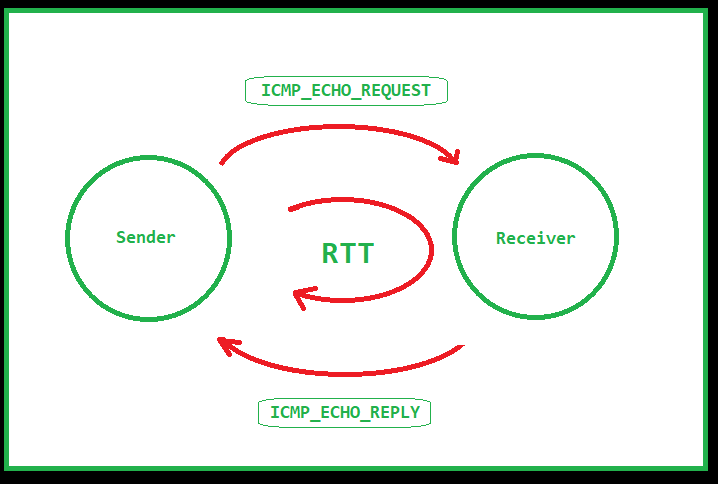
Ping is quite possibly one of the most well known tools available. Simply put, ping sends an “are you there?” message to a remote host. If the host is, in fact, there, it returns a “yup, I’m here” message. It does this using a protocol known as ICMP, or Internet Control Message Protocol. ICMP was designed to be an error reporting protocol and has a wide variety of uses that we won’t go into here.
Ping uses two message types of ICMP, type 8 or Echo Request and type 0 or Echo Reply. When you issue a ping command, the source sends an ICMP Echo Request to the destination. If the destination is available, and allowed to respond, then it replies with an ICMP Echo Reply. Once the message returns to the source, the ping command displays a success message as well as the RTT or Round Trip Time. RTT can be an indicator of the latency between the source and destination.
Note: ICMP is typically a low priority protocol meaning that the RTT is not guaranteed to match what the RTT is to a higher priority protocol such as TCP.
When the ping command completes, it displays a summary of the ping session. This summary tells you how many packets were sent and received, how much packet loss there was, and statistics on the RTT of the traffic. Ping is an excellent first step to identifying whether or not a destination is “alive” or not. Keep in mind, however, that some networks block ICMP traffic, so a failure to respond is not a guarantee that the destination is offline.
$ ping google.com
PING google.com (172.217.10.46): 56 data bytes
64 bytes from 172.217.10.46: icmp_seq=0 ttl=56 time=15.740 ms
64 bytes from 172.217.10.46: icmp_seq=1 ttl=56 time=14.648 ms
64 bytes from 172.217.10.46: icmp_seq=2 ttl=56 time=11.153 ms
64 bytes from 172.217.10.46: icmp_seq=3 ttl=56 time=12.577 ms
64 bytes from 172.217.10.46: icmp_seq=4 ttl=56 time=22.400 ms
64 bytes from 172.217.10.46: icmp_seq=5 ttl=56 time=12.620 ms
^C
--- google.com ping statistics ---
6 packets transmitted, 6 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 11.153/14.856/22.400/3.689 ms
The example above shows a ping session to google.com. From the output you can see the IP address being contacted, the sequence number of each packet sent, and the round trip time. 6 packets were sent with an average RTT of 14ms.
One thing to note about the output above and the ping utility in general. Ping is strictly an IPv4 tool. If you’re testing in an IPv6 network you’ll need to use the ping6 utility. The ping6 utility works roughly identical to the ping utility with the exception that it uses IPv6.
Traceroute
Traceroute is a finicky beast. The premise is that you can use this tool to identify the path between a source and destination point. That’s mostly true, with a couple of caveats. Let’s start by explaining how traceroute works.
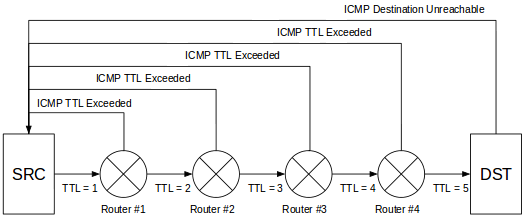
Think of traceroute as a string of ping commands. At each step along the path, traceroute identifies the IP of the hop as well as the latency to that hop. But how is it finding each hop? Turns out, it’s using a bit of trickery.
Traceroute uses UDP or ICMP, depending on the OS. On a typical *nix system it uses UDP by default, sending traffic to port 33434 by default. On a Windows system it uses ICMP. As with ping, traceroute can be blocked by not responding to the protocol/port being used.
When you invoke traceroute you identify the destination you’re trying to reach. The command begins by sending a packet to the destination, but it sets the TTL of the packet to 1. This is significant because the TTL value determines how many hops a packet is allowed to pass through before an ICMP Time Exceeded message is returned to the source. The trick here is to start the TTL at 1 and increment it by 1 after the ICMP message is received.
$ traceroute google.com
traceroute to google.com (172.217.10.46), 64 hops max, 52 byte packets
1 192.168.1.1 (192.168.1.1) 1747.782 ms 1.812 ms 4.232 ms
2 10.170.2.1 (10.170.2.1) 10.838 ms 12.883 ms 8.510 ms
3 xx.xx.xx.xx (xx.xx.xx.xx) 10.588 ms 10.141 ms 10.652 ms
4 xx.xx.xx.xx (xx.xx.xx.xx) 14.965 ms 16.702 ms 18.275 ms
5 xx.xx.xx.xx (xx.xx.xx.xx) 15.092 ms 16.910 ms 17.127 ms
6 108.170.248.97 (108.170.248.97) 13.711 ms 14.363 ms 11.698 ms
7 216.239.62.171 (216.239.62.171) 12.802 ms
216.239.62.169 (216.239.62.169) 12.647 ms 12.963 ms
8 lga34s13-in-f14.1e100.net (172.217.10.46) 11.901 ms 13.666 ms 11.813 ms
Traceroute displays the source address of the ICMP message as the name of the hop and moves on to the next hop. When the source address matches the destination address, traceroute has reached the destination and the output represents the route from the source to the destination with the RTT to each hop. As with ping, the RTT values shown are not necessarily representative of the real RTT to a service such as HTTP or SSH. Traceroute, like ping, is considered to be lower priority so RTT values aren’t guaranteed.
There is a second caveat with traceroute you should be aware of. Traceroute shows you the path from the source to the destination. This does not mean that the reverse is true. In fact, there is no current way to identify the path from the destination to the source without running a second traceroute from the destination. Keep this in mind when troubleshooting path issues.
Netstat
Netstat is an indispensable tool that shows you all of the network connections on an endpoint. That is, by invoking netstat on your local machine, all of the open ports and connections are shown. This includes connections that are not completely established as well as connections that are being torn down.
$ sudo netstat -anptu
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:25 0.0.0.0:* LISTEN 4417/master
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 2625/java
tcp 0 0 192.168.1.38:389 0.0.0.0:* LISTEN 559/slapd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1180/sshd
tcp 0 0 192.168.1.38:37190 192.168.1.38:389 ESTABLISHED 2625/java
tcp 0 0 192.168.1.38:389 192.168.1.38:45490 ESTABLISHED 559/slapd
The output above shows several different ports in a listening state as well as a few established connections. For listening ports, if the source address is 0.0.0.0, it is listening on all available interfaces. If there is an IP address instead, then the port is open only on that specific interface.
The established connections show the source and destination IPs as well as the source and destination ports. The Recv-Q and Send-Q fields show the number of bytes pending acknowledgement in either direction. Finally, the PID/Program name field shows the process ID and the name of the process responsible for the listening port or connection.
Netstat also has a number of switches that can be used to view other information such as the routing table or interface statistics. Both IPv4 and IPv6 are supported. There are switches to limit to either version, but both are displayed by default.
In recent years, netstat has been superseded by the ss command. You can find more information on the ss command in this post by Ken Hess.
Conclusion
As you can see, these tools are invaluable when troubleshooting network issues. As a network or systems administrator, I highly recommend becoming intimately familiar with these tools. Having these available may save you a lot of time troubleshooting.
SPOFs, or a Single Points of Failure, are the points in a system that can cause a complete failure of the overall system. These can be both technological and operational in nature. Creating a truly resilient system means identifying and mitigating as many of these as you can. Truly resilient systems minimize SPOFs and put mechanisms in place to handle any SPOFs that can’t be immediately dealt with and minimize the consequences of any given failure.
Single Point of Failure
A single point of failure is a part of a system that, if it fails, will stop the entire system from working. SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
If we look back at the first post in this series, there are a multitude of SPOFs that need to be handled. Our first deployment is a single server with a single network feed. The following is a list of immediate SPOFs that need to be dealt with:
Single network connection
Single network interface
Single server
Single database
Monolithic application
Single hard drive
Single power supply
All of these SPOFs are technological in nature. We didn’t explore the operational workflows around this deployment, so identifying non-technological is beyond this particular exercise.
In the second post, we discussed mitigation of some of these SPOFs. Primarily, we distributed services to multiple servers, mitigating the single server as a SPOF. However, the failure of any single service results in the failure of the whole.
Mitigating SPOFs comes down to identifying where you depend on a single resource and developing a strategy to mitigate it. In our previous example, we identified the server as a SPOF and mitigated it by using multiple servers. However, since we’re still dealing with single instances of dependent services, mitigating this SPOF doesn’t help us much.
If we duplicated each service and placed each on its own server, we’re in a much better situation. Failure of any single server, while potentially degrading overall service, will not result in the complete failure of the system. So, we need to identify SPOFs while keeping in mind any dependencies between components.
Now that we’ve deployed multiple copies of each service, what other SPOFs still exist? Each server only has a single power supply, there’s only one network interface on each server, and the overall system only has a single network feed. So we can continue mitigating SPOFs by duplicating each component. For instance, we can add multiple network interfaces to each server, deploy additional network connections, and ensure there are multiple power supplies in each server.
There is a point of diminishing returns, however. Given unlimited time and resources, every SPOF can be eliminated, but is that realistic? In a real world scenario, there are often constraints that cannot be easily overcome. For instance, it may not be possible to deploy multiple network connections in a given location. However, it may be possible to distribute services across multiple locations, thereby eliminating multiple SPOFs in one fell swoop.
By deploying to two or more locations, you potentially eliminate multiple SPOFs. Each location will have a network connection, separate power, and separate facilities. Mitigating each of these SPOFs increases the resiliency of the overall system.
In other situations, there may be financial constraints. Deploying to multiple locations may be cost prohibitive, so mitigations need to come in different forms. Adding additional network interfaces and connections help mitigate network failures. Multiple power supplies mitigate hardware failures. And deploying UPS power or, if possible, separate power sources, mitigates power problems.
Each deployment has its own challenges for resiliency and engineers need to work to identify and mitigate each one.
In the previous article, we discussed a very simple monolithic deployment. One server with all of the relevant services necessary to make our application work. We discussed details such as drive layout, package installation, and some basic security controls.
In this article, we’ll expand that design a bit by deploying individual services and explain, along the way, why we do this. This won’t solve the single point of failure issues that we discussed previously, but these changes will move us further down the path of a reliable and resilient deployment.
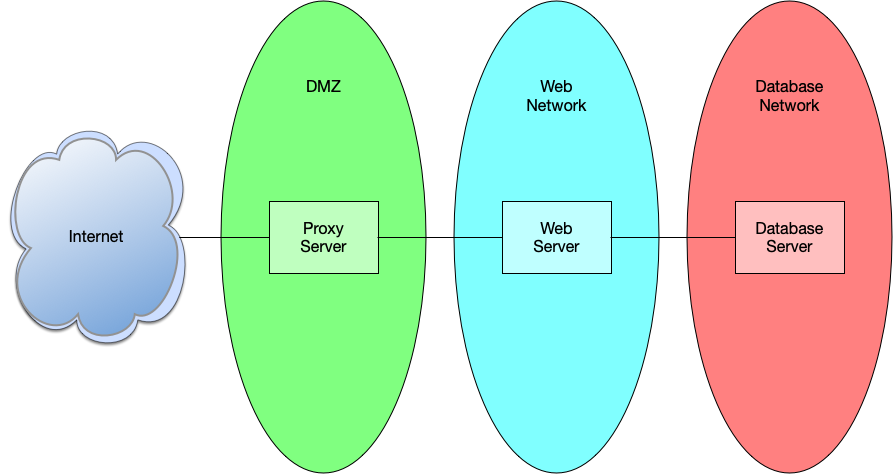
Let’s do a quick recap first. Our single server deployment includes a simple website application and a database. We can break this up into two, possibly three distinct applications to be deployed. The database is straightforward. Then we have the website itself which we can break into a proxy server for security and the primary web server where the application will exist.
Why a proxy server, you may ask. Well, our ultimate goals are security, reliability, and resiliency. Adding an additional service may sound counter-intuitive, but with a proxy server in front of everything we gain some additional security as well as a means to load balance when we eventually scale out the application for resiliency and reliability purposes.
The security comes by adding an additional layer between the client and the protected data. If the proxy server is compromised, the attacker still has to move through additional layers to get to the data. Additionally, proxy servers rarely contain any sensitive data on them. ie, there are no usernames or passwords located on the proxy server.
In addition to breaking this deployment into three services, we also want to isolate those services into purpose-built networks. The proxy server should live in what is commonly called a DMZ network, we can place the web server in a network designated for web servers, and the database goes into a database network.
Segmented networks
Keeping these services separate allows you to add additional layers of protection such as firewall rules that limit access to each asset. For instance, the proxy server typically needs ports 80 and 443 open to allow http and https traffic. The web server requires whatever port the web application is running on to be open, and the database server only needs the database port open. Additionally, you can limit the source of the traffic as well. Proxy servers are typically open to the world, but the web server only needs to be open to the proxy server, and the database server only needs to be open to the web server.
With this new deployment strategy, we’ve increased the number of servers and added the need for a lot of new configuration which increases complexity a bit. However, this provides us with a number of benefits. For starters, we have more control over the security of each system, allowing us to reduce the attack surface of each individual server. We’ve also added the ability to place firewalls in between each server, limiting the traffic to specific ports and, in certain instances, from specific hosts.
Separating the services to their own servers also has the potential of allowing for horizontal scaling. For instance, you can run multiple proxy and web servers, allowing additional resiliency in case of the failure of one or more servers. Scaling the proxy servers requires some additional network wizardry or the presence of a load balancing device of some sort, but the capability is there. We’ll discuss horizontal scaling in a future post.
The downside of a deployment like this is the complexity and the additional overhead required. Instead of a single server to maintain, you now have three. You’ve also added firewalls to the mix which also need maintenance. There’s also additional latency added due to the network overhead of communication between the servers. This can be reduced through a number of techniques such as caching, but is generally not an issue for typical web applications.
The example we’ve used, thus far, is quite simplistic and this is not necessarily a good strategy for a small web application deployment, but provides an easy to understand example as we expand our deployment options. In future posts we’ll look at horizontal scaling, load balancing, and we’ll start digging into new technologies such as containerization.
I’ve recently been reading Wired for War by P.W. Singer and one of the concepts he mentions in the book is Network Enhanced Telepathy. This struck me as not only something that sounds incredibly interesting, but something that we’ll probably see hit mainstream in the next 5-10 years.
According to Wikipedia, telepathy is “the purported transmission of information from one person to another without using any of our known sensory channels or physical interaction.“ In other words, you can think *at* someone and communicate. The concept that Singer talks about in the book isn’t quite as “mystical” since it uses technology to perform the heavy lifting. In this case, technology brings fantasy into reality.
Scientists have alreadydeveloped methods to “read” thoughts from the human mind. These methods are by no means perfect, but they are a start. As we’ve seen with technology across the board from computers to robotics, electric cars to rockets, technological jumps may ramp up slowly, but then they rocket forward at a deafening pace. What seems like a trivial breakthrough at the moment may well lead to the next step in human evolution.
What Singer describes in the book is one step further. If we can read the human mind, and presumably write back to it, then adding a network in-between, allowing communication between minds, is obvious. Thus we have Network Enhanced Telepathy. And, of course, with that comes all of the baggage we associate with networks today. Everything from connectivity issues and lag to security problems.
The security issues associated with something like this range from inconvenient to downright horrifying. If you thought social engineering was bad, wait until we have a direct line straight into someone’s brain. Today, security issues can result in stolen data, denial of service issues, and, in some rare instances, destruction of property. These same issues may exist with this new technology as well.
Stolen data is pretty straightforward. Could an exploit allow an attacker to arbitrarily read data from someone’s mind? How would this work? Could they pinpoint the exact data they want, or would they only have access to the current “thoughts” being transmitted? While access to current thoughts might not be as bad as exact data, it’s still possible this could be used to steal important data such as passwords, secret information, etc. Pinpointing exact data could be absolutely devastating. Imagine, for a moment, what would happen if an attacker was able to pluck your innermost secrets straight out of your mind. Everyone has something to hide, whether that’s a deep dark secret, or maybe just the image of themselves in the bathroom mirror.
I’ve seen social engineering talks wherein the presenter talks about a technique to interrupt a person, mid-thought, and effectively create a buffer overflow of sorts, allowing the social engineer to insert their own directions. Taken to the next level, could an attacker perform a similar attack via a direct link to a person’s mind? If so, what access would the attacker then attain? Could we be looking at the next big thing in brainwashing? Merely insert the new programming, directly into the user.
How about Denial of Service attacks or physical destruction? Could an attacker cause physical damage in their target? Is a connection to the mind enough access to directly modify the cognitive functions of the target? Could an attacker induce something like Locked-In syndrome in a user? What about blocking specific functions, preventing the user from being able to move limbs, or speak? Since the brain performs regulatory control over the body, could an attacker modify the temperature, heart rate, or even induce sensations in their target? These are truly scary scenarios and warrant serious thought and discussion.
Technology is racing ahead at breakneck speeds and the future is an exciting one. These technologies could allow humans to take that next evolutionary step. But as with all technology, we should be looking at it with a critical eye. As technology and biology become more and more intertwined, it is essential that we tread carefully and be sure to address potential problems long before they become a reality.
The Cloud, hailed as a panacea for all your IT related problems. Need storage? Put it in the Cloud. Email? Cloud. Voice? Wireless? Logging? Security? The Cloud is your answer. The Cloud can do it all.
But what does that mean? How is it that all of these problems can be solved by merely signing up for various cloud services? What is the cloud, anyway?
Unfortunately, defining what the cloud actually is remains problematic. It means many things to many people. The cloud can be something “simple” like extra storage space or email. Google, Dropbox, and others offer a service that allows you to store files on their servers, making them available to you from “anywhere” in the world. Anywhere, of course, if the local government and laws allow you to access the services there. These services are often free for a small amount of space.
Google, Microsoft, Yahoo, and many, many others offer email services, many of them “free” for personal use. In this instance, though, free can be tricky. Google, for instance, has algorithms that “read” your email and display advertisements based on the results. So while you may not exchange money for this service, you do exchange a level of privacy.
Cloud can also be pure computing power. Virtual machines running a variety of operating systems, available for the end-user to access and run whatever software they need. Companies like Amazon have turned this into big business, offering a full range of back-end services for cloud-based servers. Databases, storage, raw computing power, it’s all there. In fact, they have developed APIs allowing additional services to be spun up on-demand, augmenting existing services.
As time goes on, more and more services are being added to the cloud model. The temptation to drop self-hosted services and move to the cloud is constantly increasing. The incentives are definitely there. Cloud services are affordable, and there’s no need for additional staff for support. All the benefits with very little of the expense. End-users have access to services they may not have had access to previously, and companies can save money and time by moving services they use to the cloud.
But as with any service, self-hosted or not, there are questions you should be asking. The answers, however, are sometimes a bit hard to get. But even without direct answers, there are some inferences you can make based on what the service is and what data is being transferred.
Data being accessible virtually anywhere, at any time, is one of major draws of cloud services. But there are downsides. What happens when the service is inaccessible? For a self-hosted service, you have control and can spend the necessary time to bring the service back up. In some cases, you may have the ability to access some or all of the data, even without the service being fully restored. When you surrender your data to the cloud, you are at the mercy of the service provider. Not all providers are created equal and you cannot expect uniform performance and availability across all providers. This means that in the event of an outage, you are essentially helpless. Keeping local backups is definitely an option, but oftentimes you’re using the cloud so that you don’t need those local backups.
Speaking of backups, is the cloud service you’re using responsible for backups? Will they guarantee that your data will remain safe? What happens if you accidentally delete a needed file or email? These are important issues that come up quite often for a typical office. What about the other side of the question? If the service is keeping backups, are those backups secure? Is there a way to delete data, permanently, from the service? Accidents happen, so if you’ve uploaded a file containing sensitive information, or sent/received an email with sensitive information, what recourse do you have? Dropbox keeps snapshots of all uploaded data for 30 days, but there doesn’t seem to be an official way to permanently delete a file. There are a number of articles out there claiming that this is possible, just follow the steps they provide, but can you be completely certain that the data is gone?
What about data security? Well, let’s think about the data you’re sending. For an email service, this is a fairly simple answer. Every email goes through that service. In fact, your email is stored on the remote server, and even deleted messages may hang around for a while. So if you’re using email for anything sensitive, the security of that information is mostly out of your control. There’s always the option of using some sort of encryption, but web-based services rarely support that. So data security is definitely an issue, and not necessarily an issue you have any control over. And remember, even the “big guys” make mistakes. Fishnet Security has an excellent list of questions you can ask cloud providers about their security stance.
Liability is an issue as well, though you may not initially realize it. Where, exactly, is your data stored? Do you know? Can you find out? This can be an important issue depending on what your industry is, or what you’re storing. If your data is being stored outside of your home country, it may be subject to the laws and regulations of the country it’s stored in.
There are a lot of aspects to deal with when thinking about cloud services. Before jumping into the fray, do your homework and make sure you’re comfortable with giving up control to a third party. Once you give up control, it may not be that easy to reign it back in.
I was debugging an odd network issue lately that turned out to have a pretty simple explanation. A client on the network was intermittently experiencing significant delays in accessing the network. Upon closer inspection, it turned out that prior to the delay, the client was being left idle for long periods of time. With this additional information it was pretty easy to identify that there was likely a connection between the client and server that was being torn down for being idle.
So in the end, the cause of the problem itself was pretty simple to identify. The fix, however, is more of a conundrum. The obvious answer is to adjust the timers and prevent the connection from being torn down. But what timers should be adjusted? There are the keepalive timers on the client, the keepalive timers on the server, and the idle teardown timers on the firewall in the middle.
TCP keepalive handling varies between operating systems. If we look at the three major operating systems, Linux, Windows, and OS X, then we can make the blanket statement that, by default, keepalives are sent after two hours of idle time. But, most firewalls seem to have a default TCP teardown timer of one hour. These defaults are not conducive to keeping idle connections alive.
The optimal scenario for timeouts is for the clients to have a keepalive timer that fires at an interval lower than that of the idle tcp timeout on the firewall. The actual values to use, as well as which devices should be changed, is up for debate. The firewall is clearly the easier point at which to make such a change. Typically there are very few firewall devices that would need to be updated as compared to the larger number of client devices. Additionally, there will likely be fewer firewalls added to the network over time, so ensuring that timers are properly set is much easier. On the other hand, the defaults that firewalls are generally configured with have been chosen specifically by the vendor for legitimate reasons. So perhaps the clients should conform to the setting on the firewall? What is the optimal solution?
And why would we want to allow idle connections anyway? After all, if a connection is idle, it’s not being used. Clearly, any application that needed a connection to remain open would send some sort of keepalive, right? Is there a valid reason to allow these sorts of connections for an extended period of time?
As it turns out, there are valid reasons for connections to remain active, but idle. For instance, database connections are often kept for longer periods of time for performance purposes. The TCP handshake can take a considerable amount of time to perform as opposed to the simple matter of retrieving data from a database. So if the database connection remains established, additional data can be retrieved without the overhead of TCP setup. But in these instances, shouldn’t the application ensure that keepalives are sent so that the connection is not prematurely terminated by an idle timer somewhere along the data path? Well, yes. Sort of. Allow me to explain.
When I first discovered the source of the network problem we were seeing, I chalked it up to lazy programming. While it shouldn’t take much to add a simple keepalive system to a networked application, it is extra work. As it turns out, however, the answer isn’t quite that simple. All three major operating systems, Windows, Linux, and OS X, all have kernel level mechanisms for TCP keepalives. Each OS has a slightly different take on how keepalive timers should work.
The interval between the last data packet sent (simple ACKs are not considered data) and the first keepalive probe; after the connection is marked to need keepalive, this counter is not used any further
tcp_keepalive_intvl
The interval between subsequential keepalive probes, regardless of what the connection has exchanged in the meantime
tcp_keepalive_probes
The number of unacknowledged probes to send before considering the connection dead and notifying the application layer
OS X works quite similar to Linux, which makes sense since they’re both *nix variants. OS X has four parameters that can be set.
keepidle
Amount of time, in milliseconds, that the connection must be idle before keepalive probes (if enabled) are sent. The default is 7200000 msec (2 hours).
keepintvl
The interval, in milliseconds, between keepalive probes sent to remote machines, when no response is received on a keepidle probe. The default is 75000 msec.
keepcnt
Number of probes sent, with no response, before a connection is dropped. The default is 8 packets.
always_keepalive
Assume that SO_KEEPALIVE is set on all TCP connections, the kernel will periodically send a packet to the remote host to verify the connection is still up.
Windows acts very differently from Linux and OS X. Again, there are three parameters, but they perform entirely different tasks. All three parameters are registry entries.
KeepAliveInterval
This parameter determines the interval between TCP keep-alive retransmissions until a response is received. Once a response is received, the delay until the next keep-alive transmission is again controlled by the value of KeepAliveTime. The connection is aborted after the number of retransmissions specified by TcpMaxDataRetransmissions have gone unanswered.
KeepAliveTime
The parameter controls how often TCP attempts to verify that an idle connection is still intact by sending a keep-alive packet. If the remote system is still reachable and functioning, it acknowledges the keep-alive transmission. Keep-alive packets are not sent by default. This feature may be enabled on a connection by an application.
TcpMaxDataRetransmissions
This parameter controls the number of times that TCP retransmits an individual data segment (not connection request segments) before aborting the connection. The retransmission time-out is doubled with each successive retransmission on a connection. It is reset when responses resume. The Retransmission Timeout (RTO) value is dynamically adjusted, using the historical measured round-trip time (Smoothed Round Trip Time) on each connection. The starting RTO on a new connection is controlled by the TcpInitialRtt registry value.
There’s a pretty good reference page with information on how to set these parameters that can be found here.
We still haven’t answered the question of optimal settings. Unfortunately, there doesn’t seem to be a correct answer. The defaults provided by most firewall vendors seem to have been chosen to ensure that the firewall does not run out of resources. Each connection through the firewall must be tracked. As a result, each connection uses up a portion of memory and CPU. Since both memory and CPU are finite resources, administrators must be careful not to exceed the limits of the firewall platform.
There is some good news. Firewalls have had a one hour tcp timeout timer for quite a while. As time has passed and new revisions of firewall hardware are released, the CPU has become more powerful and the amount of memory in each system has grown. The default one hour timer, however, has remained in place. This means that modern firewall platforms are much better prepared to handle an increase in the number of connections tracked. Ultimately, the firewall platform must be monitored and appropriate action taken if resource usage becomes excessive.
My recommendation would be to start by setting the firewall tcp teardown timer to a value slightly higher than that of the clients. For most networks, this would be slightly over two hours. The firewall administrator should monitor the number of connections tracked on the firewall as well as the resources used by the firewall. Adjustments should be made as necessary.
If longer lasting idle connections are unacceptable, then a slightly different tactic can be used. The firewall teardown timer can be set to a level comfortable to the administrator of the network. Problematic clients can be updated to send keepalive packets at a shorter interval. These changes will likely only be necessary on servers. Desktop systems don’t have the same need as servers for long-term establishment of idle connections.
This week, Adobe released a security patch for their CS5 product line. While Adobe releasing security patches isn’t really that surprising given their track record with vulnerable products, what is somewhat surprising are the circumstances surrounding the patch. Adobe released the patch somewhat reluctantly.
Sometime in May, possibly earlier, Adobe was made aware of a fairly severe security vulnerability in their CS5 product line. A specially crafted image file was enough to compromise the victim’s computer. Obviously this is a pretty severe flaw and should be fixed ASAP, right? Well, Adobe didn’t really see it that way. Their initial response to the problem was that users who wanted a fixed version would have to pay to upgrade to the CS6 product line, in which the flaw was patched. Eventually they decided to backport the patch to the CS5 version.
Adobe’s initial response and their eventual capitulation leads to a broader discussion. Given any security problem, or even any bug in general, who is responsible for fixing it? The vendor, of course, right? Well… Maybe?
In a perfect world, there would be no bugs, security or otherwise. In a slightly less perfect world, all bugs would be resolved before a product is retired. But neither world exists and bugs seem to prevail. So, given that, who’s problem is it anyway?
There are a lot of justifications vendors make as to when they’ll patch, how they’ll support something, and, of course, excuses. It’s not an easy problem for vendors, though, and some vendors put a lot of thought into their policies. They don’t always get them right, and there’s never a way to make everyone happy.
Patching generally follows a product lifecycle. While the product is supported, patching happens as a normal course of business. When a product is retired, some companies put together a support plan with For instance, when Cisco announces that a product has entered the End-of-Life cycle, they lay out a multi-year plan for support. Typically this involves regular software maintenance for a year, security releases for 2-3 years, and then hardware maintenance for the remainder. This gives businesses ample time to deal with finding a suitable replacement.
Unfortunately, not all vendors act responsibly and often customers are left high and dry when a product is suddenly obsoleted. Depending on the vendor, this sometimes leads to discussions about the possibility of legislation forcing vendors to support products, or to at least address security vulnerabilities. If something like this were to pass, where does it end? Are vendors forced to support products forever? Should they only have to fix severe security problems? And what constitutes a severe security problem?
There are a multitude of reasons that bugs, security or otherwise, are not dealt with. Some justifiable, others not. Working in networking, the primary excuse I’ve heard from hardware vendors over the year is that the management interface of their product is not intended to be on a public network where it can be attacked. Or that the management interfaces should be put behind a firewall where it can’t be attacked. These excuses are garbage, of course, but some vendors just continue to give them. And, unfortunately, you’re not always in a position to drop a vendor and move elsewhere. So, we do what we can to secure the systems and move on.
And sometimes the problem isn’t the vendor, but the customer. How long has it been since Microsoft phased out older versions of it’s Windows operating system? Windows XP is relatively recent, but it’s been a number of years since Windows 2000 was phased out. Or how about Windows 98, 95, and even Windows NT? And customers still have these deployed in their networks. Hell, I know of at least one OS/2 Warp system that’s still deployed in a Telco Central Office!
There is a basis for some regulation, however, and it may affect vendors. When the security of a particular product can significantly impact the public, it can be argued that regulation is necessary. The poster child for this argument are SCADA systems which seem to be perpetually riddled with security holes, mostly due to outdated operating systems.
SCADA systems are what typically control the electrical grid or nuclear power plants. For obvious reasons, security problems with these systems are a deadly serious problem. I often hear that these systems should be air gapped from the Internet, but the lure of easy access and control often pushes users to ignore this advice.
So should SCADA systems be regulated? It’s obvious that the regulations in place already for the industries they are used in aren’t working, so what makes us think that more regulation will help? And if we regulate and force vendors to provide patches for security problems, what makes us think that industries will install them?
This is a complex problem and there are no easy answers. The best we can hope for is a competent administrator who knows how to handle security and deal with threats properly. Until then, let’s hope for incompetent criminals.
It is no surprise that security is at the forefront of everyone’s minds these days. With high profile breaches, to script kiddies wreaking havoc across the Internet, it is obvious that there are some weaknesses that need to be addressed.
In most cases, complete network redesigns are out of the question. This can be extremely invasive and costly. However, it may be possible to augment the existing network in such a manner as to add additional layers of security. It’s also possible that this may lead to the possibility of being able to make even more changes down the road.
So what do I mean by this? Allow me to explain…
Many networks are fairly simple with only a few subnets, typically a user and a server subnet. Sometimes there’s a bit of complexity on the user side, creating subnets per department, or subnets per building. Often this has more to do with manageability of users rather than security. Regardless, it’s a good practice that can be used to make a network more secure in the long run.
What is often neglected is the server side of things. Typically, there are one, maybe two subnets. Outside users are granted access to the standard web ports. Sometimes more ports such as ssh and ftp are opened for a variety of reasons. What administrators don’t realize, or don’t intend is that they’re allowing outsiders direct access to their core servers, without any sort of security in front of it. Sure, sure, there might be a firewall, but a firewall is there to ensure you only come in on the proper ports, right? If your traffic is destined for port 80, it doesn’t matter if it’s malicious or not, the firewall lets it through anyway.
But what’s the alternative? What can be done instead? Well, what about sending outside traffic to a separate network where the systems being accessed are less critical, and designed to verify traffic before passing it on to your core servers? What I’m talking about is creating a DMZ network and forcing all users through a proxy. Even a simple proxy can help to prevent many attacks by merely dropping illegal traffic and not letting it through to the core server. Proxies can also be heavily fortified with HIDS and other security software designed to look for suspicious traffic and block it.
By adding in this DMZ layer, you’ve put a barrier between your server core and the outside world. This is known as layered defense. You can add additional layers as time and resources allow. For instance, I recommend segmenting away database servers as well as identity management servers. Adding this additional segmentation can be done over time as new servers come online and old servers are retired. The end goal is to add this additional security without disrupting the network as a whole.
If you have the luxury of building a new network from the ground up, however, make sure you build this in from the start. There is, of course, a breaking point. It makes sense to create networks to segregate servers by security level, but it doesn’t make sense to segregate purely to segregate. For instance, you may segregate database and identity management servers away from the rest of the servers, but segregating Oracle servers away from MySQL servers may not add much additional security. There are exceptions, but I suggest you think long and hard before you make such an exception. Are you sure that the additional management overhead is worth the security? There’s always a cost/benefit analysis to perform.
Segregating networks is just the beginning. The purpose here is to enhance security. By segregating networks, you can significantly reduce the number of clients that need to access a particular server. The whole world may need to access your proxy servers, but only your proxy servers need to access the actual web application servers. Likewise, only your web application servers need access to your database servers. Using this information, you can tighten down your firewall. But remember, a firewall is just a wall with holes in it. The purpose is to deflect random attacks, but it does little to nothing to prevent attacks on ports you’ve opened. For that, there are other tools.
At the very edge, simplistic fire walling and generally loose HIDS can be used to deflect most attacks. As you move further within the network, additional security can be used. For instance, deploying an IPS at the very edge of the network can result in the IPS being quickly overwhelmed. Of course, you can buy a bigger, better IPS, but to what end? Instead, you can move the IPS further into the network, placing it where it be more effective. If you place it between the proxy and the web server, you’ve already ensured that the only traffic hitting the IPS is loosely validated HTTP traffic. With this knowledge, you can reduce the number of signatures the IPS needs to have, concentrating on high quality HTTP signatures. Likewise, an IPS between the web servers and database servers can be configured with high quality database signatures. You can, in general, direct the IPS to block any and all traffic that falls outside of those parameters.
As the adage goes, there is no silver bullet for security. Instead, you need to use every weapon in your arsenal and put together a solid defense. By combining all of these techniques together, you can defend against many attacks. But remember, there’s always a way in. You will not be able to stop the most determined attacker, you can only hope to slow him down enough to limit his access. And remember, securing your network is only one aspect of security. Don’t forget about the other low hanging fruit such as SQL injection, cross site scripting, and other common application holes. You may have the most secure network in existence, but a simple SQL injection attack can result in a massive data breach.