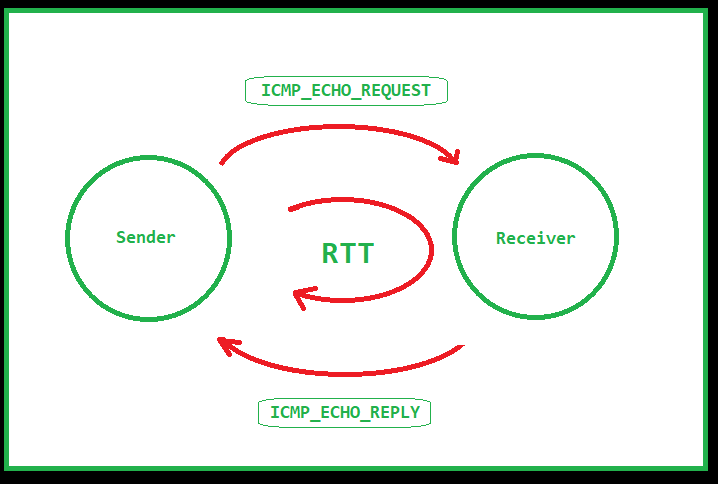
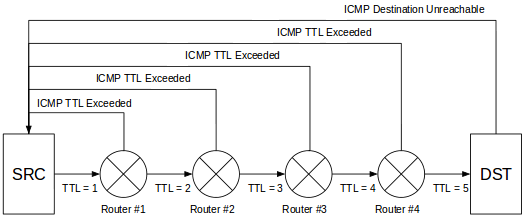
“The advantage of a bad memory is that one enjoys several times the same good things for the first time.”
Friedrich Nietzsche
This post first appeared on Redhat’s Enable Sysadmin community. You can find the post here.
Memory is a funny construct. What we remember is often not what happened, or even the order it happened in. One of the earliest memories I have about technology was a trip my father and I took. We drove to Manhattan, on a mission to buy a Christmas gift for my mother. This crazy new device, The Itty Bitty Book Light, had come out recently and, being an avid reader, my mother had to have one.

We drove to Manhattan, on a mission to buy a Christmas gift for my mother. This crazy new device, The Itty Bitty Book Light, had come out recently and, being an avid reader, my mother had to have one.
After navigating the streets of Manhattan and finding a parking spot, we walked down the block to what turned out to be a large bookstore. You’ve seen bookstores like this on TV and in the movies. It looks small from the outside, but once you walk in, the store is endless. Walls of books, sliding ladders, tables with books piled high. It was pretty incredible, especially for someone like me who loves reading.
But in this particular store, there was something curious going on. One of the tables was surrounded by adults, awed and whispering between one another. Unsure of what was going on, we approached. After pushing through the crowd, what I saw drew me in immediately. On the table, surrounded by books, was a small grey box, the Apple Macintosh. It was on, but no one dared approach it. No one, that is, except me. I was drawn like a magnet, immediately grokking that the small puck like device moved the pointer on the screen. Adults gasped and murmured, but I ignored them all and delved into the unknown. The year was, I believe, 1984.
Somewhere around the same time, though likely a couple years before, my father brought home a TI-99/4A computer. From what I remember, the TI had just been released, so this has to be somewhere around 1982. This machine served as the catalyst for my love of computer technology and was one of the first machines I ever cut code on.
My father tells a story about when I first started programming. He had been working on an inventory database, written from scratch, that he built for his job. I would spend hours looking over his shoulder, absorbing everything I saw. One time, he finished coding, saved the code, and started typing the command to run his code (“RUN”). Accordingly to him, I stopped him with a comment that his code was going to fail. Ignoring me as I was only 5 or 6 at the time (according to his recollection), he ran the code and, as predicted, it failed. He looked at me with awe and I merely looked back and replied “GOSUB but no RETURN”.
At this point I was off and running. Over the years I got my hands on a few other systems including the Timex Sinclair, Commodore 64 and 128, TRS-80, IBM PS/2, and finally, my very own custom built PC from Gateway 2000. Since them I’ve built hundreds of machines and spend most of my time on laptops now.
The Commodore 64 helped introduce me to the online world of Bulletin Board Systems. I spent many hours, much to the chagrin of my father and the phone bill, calling into various BBS systems in many different states. Initially I was just there to play the various door games that were available, but eventually discovered the troves of software available to download. Trading software become a big draw until I eventually stumbled upon the Usenet groups that some boards had available. I spent a lot of time reading, replying, and even ended up in more than one flame war.
My first introduction to Unix based operating systems was in college when I encountered an IBM AIX mainframe as well as a VAX. I also had access to a shell account at the local telephone company turned internet service provider. The ISP I was using helpfully sent out an email to all subscribers about the S.A.T.A.N. toolkit and how accounts found with the software in their home directories would be immediately banned. Being curious, I immediately responded looking for more information. And while my account was never banned, I did learn a lot.
At the same time, my father and I started our own BBS which grew into a local Internet Service Provider offering dial-up services. That company still exists today, though the dial-up service died off several years ago. This introduced me to networks and all the engineering that comes along with it.
From here my journey takes a bit of a turn. Since I was a kid, I’ve wanted to build video games. I’ve read a lot of books on the subject, talked to various developers (including my idol, John Carmack) and written a lot of code. I actually wrote a pacman clone, of sorts, on the Commodore 64 when I was younger. But, alas, I think I was born on the wrong coast. All of the game companies, at the time, were located on the west coast and I couldn’t find a way to get there. So, I redirected my efforts a bit and focused on the technology I could get my hands on.
Running a BBS, and later an ISP, was a great introduction into the world of networking. After working a few standard school-age jobs (fast food, restaurants, etc), I finally found a job doing tech support for an ISP. I paid attention, asked questions, and learned everything I could. I took initiative where I could, even writing a cli-based ticketing system with an mSQL database backing it.
This initiative paid of as I was moved later to the NOC and finally to Network Engineering. I lead the way, learning everything I could about ATM and helping to design and build the standard ATM-based node design used by the company for over a decade. I took over development of the in-house monitoring system, eventually rewriting it in KSH and, later, Perl. I also had a hand in development of a more modern ticketing system written in Perl that is still in use today.
I spent 20+ years as a network engineer, taking time along the way to ensure that we had Linux systems available for the various scripting and monitoring needed to ensure the network performed as it should. I’ve spent many hours writing code in shell, expect, perl, and other languages to automate updates and monitoring. Eventually, I found myself looking for a new role and a host of skills ranging from network and systems administration to coding and security.
About this time, DevOps was quickly becoming the next new thing. Initially I rejected the idea, solely responding to the “Development” and “Operations” tags that make up the name. Over time, however, I came to realize that DevOps is yet another fancy name for what I’ve been doing for decades, albeit with a few twists here and there. And so, I took a role as a DevOps Engineer.
DevOps is a fun discipline, mixing in technologies from across the spectrum in an effort to automate away everything you can. Let the machine do the work for you and spent your time on more interesting projects like building more automation. And with the advent of containers and orchestration, there’s more to do than ever.
These days I find myself leading a team of DevOps engineers, both guiding the path we take as we implement new technology and automate existing processes. I also spend a lot of time learning about new technologies both on my own and for my day job. My trajectory seems to be changing slightly as I head towards the world of the SRE. Sort of like DevOps, but a bit heavier on the development side of things.
Life throws curves and sometimes you’re not able to move in the direction you want. But if you keep at it, there’s something out there for everyone. I still love learning and playing with technology. And who knows, maybe I’ll end up writing games at some point. There’s plenty of time for another new hobby.